Why email needs context engineering
Most AI applications access external data through RAG: chunk the source material, embed it, retrieve relevant pieces, feed them to the model.
This works well on documentation and knowledge bases because those sources have clean structure, no duplication, and no concept of time.
Email is structurally different. Every reply contains the full text of every previous message as quoted content, so a 20-message thread produces roughly 210 message-equivalents of duplicated text.
Authorship matters (who said “I’ll handle this” changes its meaning entirely), but flattened threads strip that information. And conversations evolve over weeks, with decisions getting made, revised, and sometimes reversed, but vector similarity has no concept of recency.
These aren’t edge cases. They’re structural properties of email as a data format, and handling them requires six infrastructure layers between the raw Gmail or Outlook API and accurate model output: thread reconstruction, quoted text deduplication, participant attribution, temporal ordering, cross-thread linking, and attachment processing.
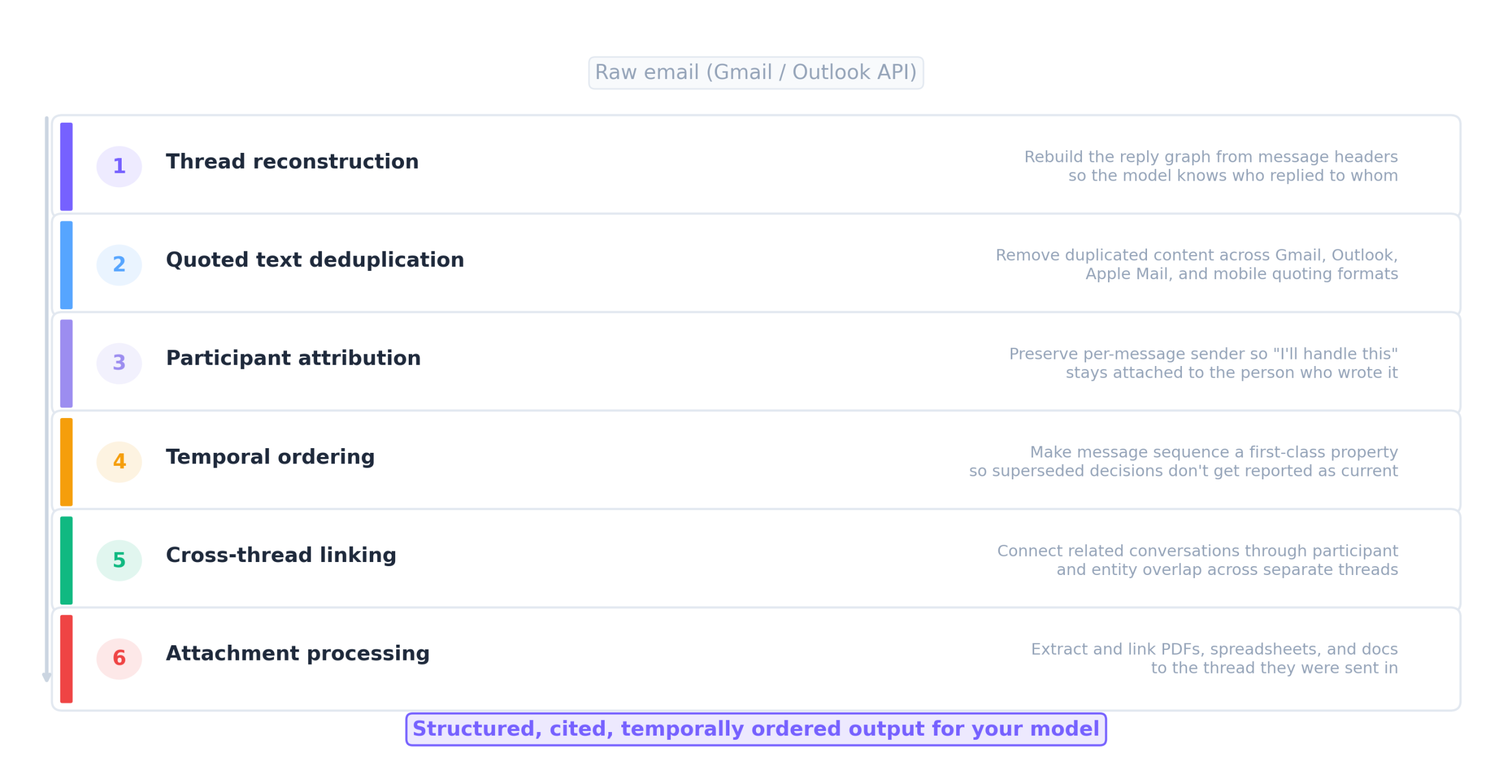
The question is how to build those layers.
Three approaches
1. Raw API + RAG
Connect the Gmail API, chunk the messages, embed and retrieve. This works for a demo. It breaks at production scale because of the duplication, attribution, and temporal problems described above.
In testing across 50 real business threads and 250 questions with verified correct answers, accuracy on business-critical questions (who committed to what, what’s the current status, what changed since last week) sat around 43%.
For a deeper analysis of why this happens, see our post on why RAG fails on email threads.
2. Build the six layers in-house
Solve each layer yourself. Auth and sync take 1-2 weeks and work as expected. This is the part that makes a 4-6 week estimate feel reasonable.
Then content parsing, thread reconstruction, entity resolution, and output structuring take another 12-24 weeks, because every new inbox reveals new quoting formats (Gmail uses “>” prefixes, Outlook uses styled div blocks, Apple Mail uses blockquote tags, mobile clients sometimes embed quotes as plain paragraphs with no structural markers), threading edge cases, and entity resolution problems that don’t throw errors but silently degrade output quality.

Across 14 teams who built this in-house, every one estimated 2-4 weeks at the start. None finished in under 14 weeks. And after declaring the initial build “done,” teams report spending 15-25% of one engineer’s ongoing time on maintenance, because email clients update their formatting, providers change API behavior, and new edge cases keep appearing with every inbox you connect.
3. Use a context engineering API
Call an API that handles all six layers upstream and returns structured, cited, temporally ordered output your model can reason over directly. Integration takes hours to days instead of months.
The cost difference

The cost that’s hardest to quantify is opportunity cost. The engineer building email parsing infrastructure is an engineer who isn’t building the product features that differentiate you, and that tradeoff compounds over 6-12 months.
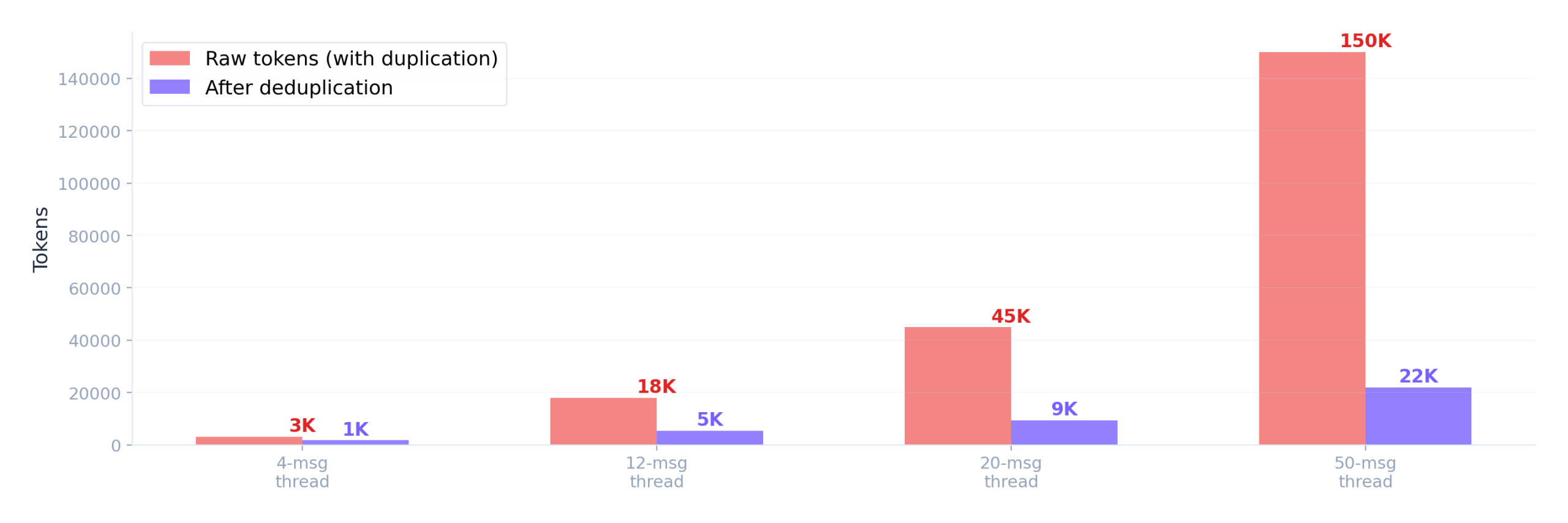
There’s also a hidden LLM inference cost. Raw email content from the Gmail API contains 4-5x token bloat from nested quoted text. A 20-message thread might produce 45,000 tokens of raw content but only contain 9,000 tokens of unique content. Deduplication before reasoning cuts inference cost proportionally.
The iGPT approach
iGPT’s Context Engine handles all six layers in one API call: thread reconstruction, quoted text deduplication across all email client formats, participant attribution, temporal ordering, cross-thread reasoning, attachment processing, and Google Drive document indexing.
import os
from igptai import IGPT
igpt = IGPT(
api_key=os.getenv("IGPT_API_KEY"),
user="user_123"
)
response = igpt.recall.ask(
input=(
"What's the current status of the Northstar deal? "
"Include open commitments and risk signals."
),
quality="cef-1-high",
output_format="json"
)
The output is structured JSON with source citations, deterministic schema, and per-user isolation. ~100ms retrieval, ~3s to first token. SOC 2 and GDPR aligned, with cloud, hybrid, or fully private on-prem deployment.
The engineering time saved goes directly into building what differentiates your product: the agent’s reasoning, the user interface, the workflow automation, the features your customers actually see.
Try it on your own email data at igpt.ai/hub/playground. Connect your inbox, ask about an active deal or project, and compare the output against what your current pipeline produces.