


iGPT Skills
If you use Claude on Pro or Max for work and you’ve ever wished it just knew what was going…
|
8 min read
RAG (retrieval-augmented generation) is the standard way to give an LLM access to external data. The pipeline is straightforward: chunk the source material into pieces, embed each piece as a vector, retrieve the most similar pieces when a question comes in, and feed them to the model as context to generate a grounded answer.
It works well for documentation, knowledge bases, product wikis, and most structured text because these sources share three properties that make chunk-and-retrieve a reasonable strategy. Each piece of text appears once, so when you chunk it and embed it you get one representation in the vector space and retrieval finds it cleanly.
Authorship is uniform or irrelevant, because a knowledge base article doesn’t change meaning depending on who wrote which paragraph. And content is non-temporal, because a product spec represents a single state, not a conversation that evolves over weeks.
Email violates all three of these properties, and the violations compound in ways that produce confident, well-structured, thoroughly wrong output.
When you pull an email thread from the Gmail API, you don’t get a clean conversation. You get a stack of messages where every reply contains the full text of every previous message as quoted content.
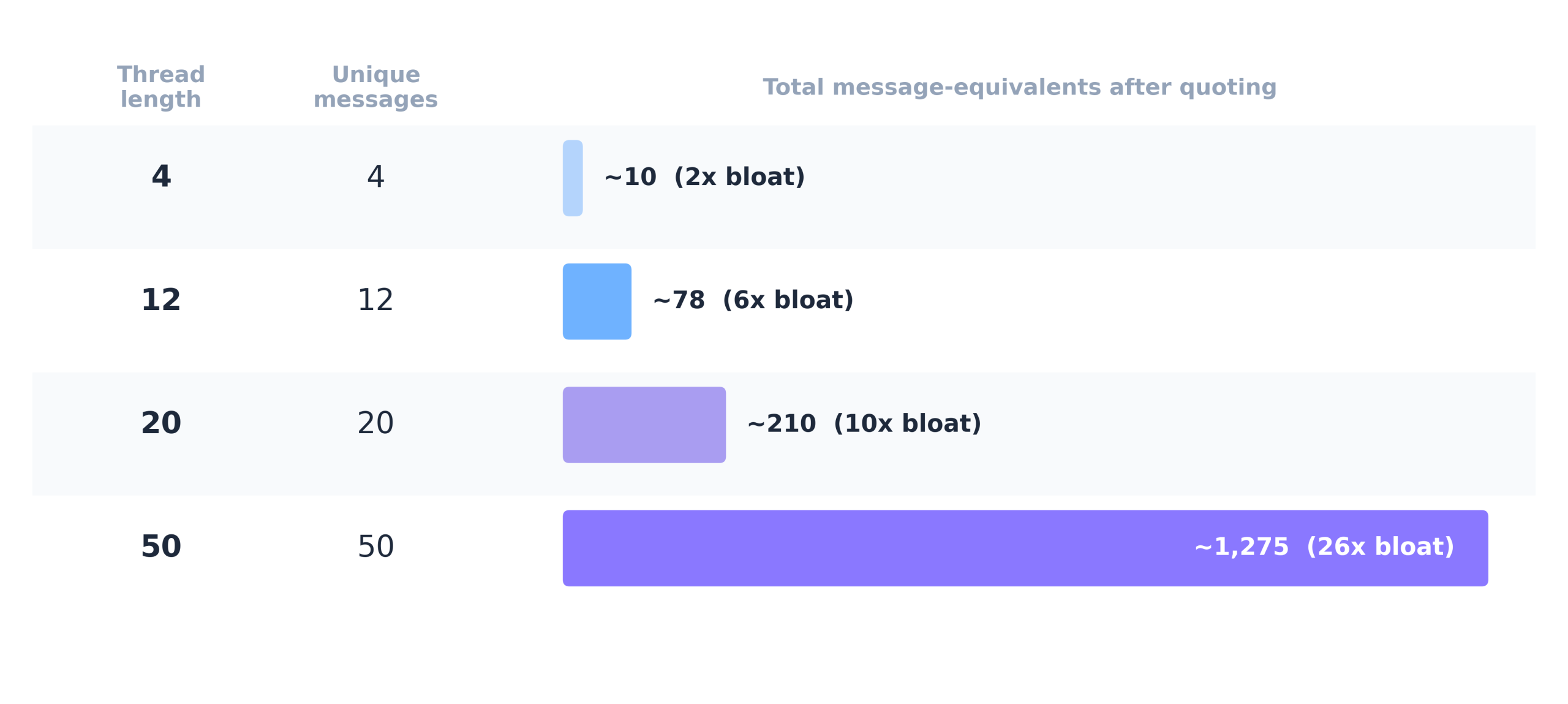
In a simple 4-message thread about Q4 budget options, Sarah’s original request (“Can you put together budget options for Q4?”) appears four times, Mike’s three budget options appear three times, and Sarah’s preference for Option B appears twice. Four unique messages produce roughly ten message-equivalents of content. The formula is n(n+1)/2, which grows quadratically with thread length.
And that’s before signatures, legal disclaimers, and confidentiality notices that get duplicated in every quoted block. On top of the duplication, email content arrives as raw MIME (base64-encoded, with multipart structures that nest HTML and plain-text versions of the same content), and the quoted text uses different formatting conventions depending on the email client.
Gmail uses “>” prefixes, Outlook uses styled div blocks, Apple Mail uses blockquote tags, and there is no standard way to tell which parts of a message are original content and which are copies from previous messages.
This is what a RAG pipeline actually receives when you point it at an inbox.
When you chunk a 20-message thread and embed the chunks, the original proposal from message #3 might appear as quoted text in messages #4, #7, #12, and #20. Each copy has slightly different formatting (different “>” depths, different line wrapping, different amounts of surrounding context), so exact deduplication misses most of them, and your vector store ends up dramatically over-representing old content relative to new content.
For example, in a thread about a product launch date, the original proposal (March 15) had five representations in the vector space because it had been quoted into five subsequent messages. The actual decision (March 22, a compromise reached later in the thread) had only one representation, as it appeared once at the end of the conversation and was never quoted in any subsequent reply.
Searching for “what launch date did the team decide on?” returned 9 of the top 14 chunks pointing to March 15 (wrong, superseded) and only 3 pointing to March 22 (correct, final).
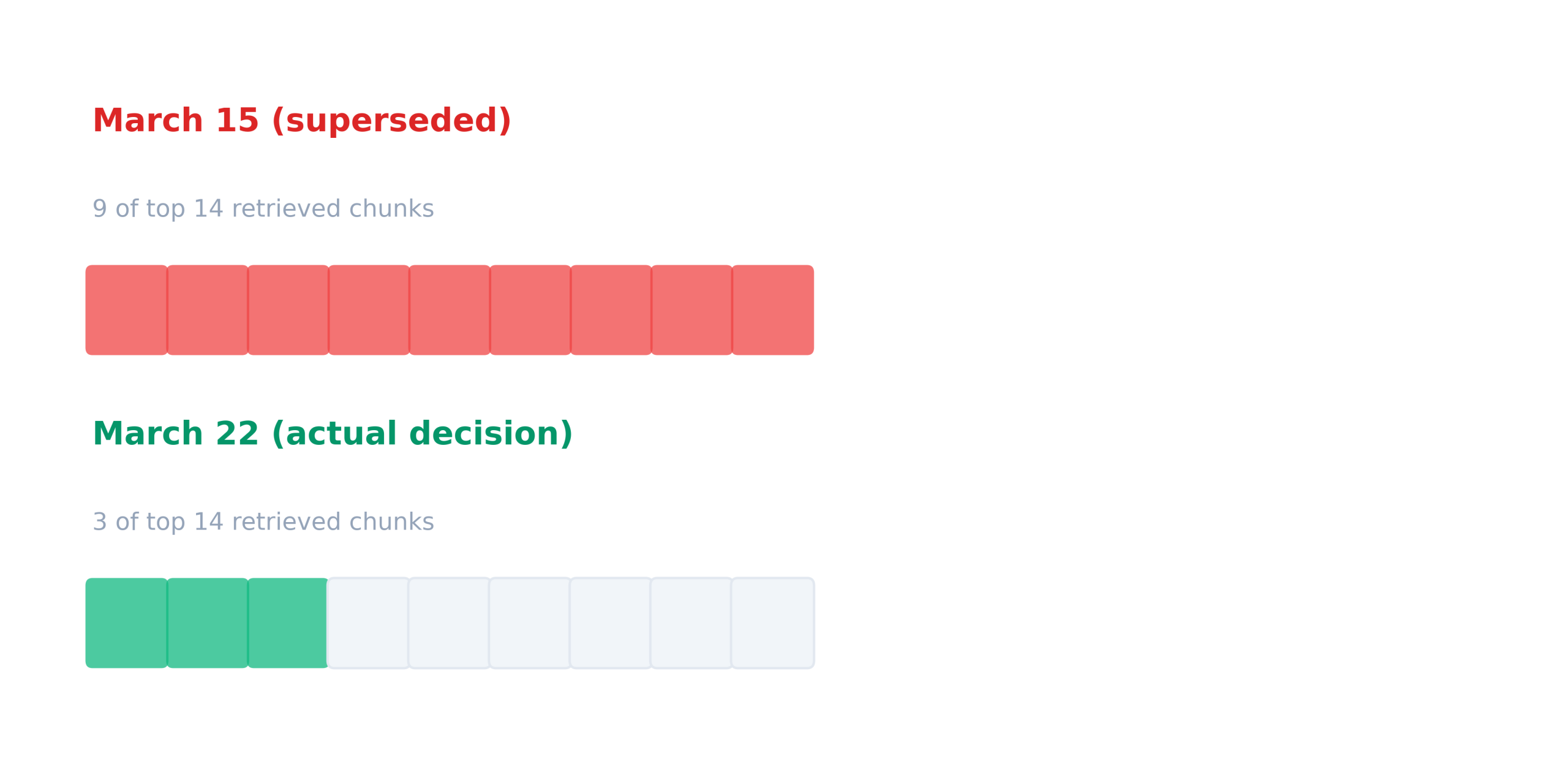
Retrieval preferred the wrong answer because it had more copies. This is exactly how vector similarity is supposed to work, and exactly why it produces the wrong result on email.
In a document, “I’ll handle the security review” means the same thing regardless of who wrote it. In an email thread with six participants, it means completely different things depending on whether the VP of Engineering or a junior analyst said it, because one of those is a commitment with organizational weight and the other is an offer that may or may not have authority behind it.
When you chunk a flattened email thread, the model sees “I’ll” in a stream of text and has to guess which “I” it refers to. It guesses wrong about 40% of the time in threads with four or more participants, and the guessing has a consistent bias: commitments get attributed to whoever wrote the most messages in the thread, because that person’s name appears most frequently in the surrounding context and the model uses frequency as a proxy for authorship.
For example, in a client renewal thread where Sarah (Account Manager) wrote “I’ll send the renewal proposal by Thursday” and Mike (Sales Director) wrote “I’ll loop in legal,” the model attributed Sarah’s commitment to Mike and Mike’s to Sarah. In business, who owns a commitment matters as much as what the commitment is.
This is the one that causes the most damage in practice, because the model can’t distinguish between “this was the team’s position three weeks ago” and “this is where things stand right now,” and the failure mode is invisible because the output always sounds current and confident regardless of whether the information is actually current.
Vector similarity has no concept of time. A message from January 5th and a message from January 25th that use similar language produce similar embeddings, and retrieval ranks them by keyword overlap and semantic similarity, neither of which correlates with recency.
For example, in a thread tracking a vendor selection, the model reported “the team decided on Vendor A” because that message had the strongest keyword match to the query. The January 20 update, which is critical context showing that the decision was being actively reversed, was dropped entirely because it ranked below the similarity threshold.
We tested 250 questions across 50 real business threads, with correct answers verified by humans who read the full threads. We ran two pipelines using the same model: standard RAG (Gmail API content, message-level chunking with quote stripping, embedded and retrieved by cosine similarity) and structured reconstruction (deduplication, entity resolution, and temporal ordering applied before the content reached the model).
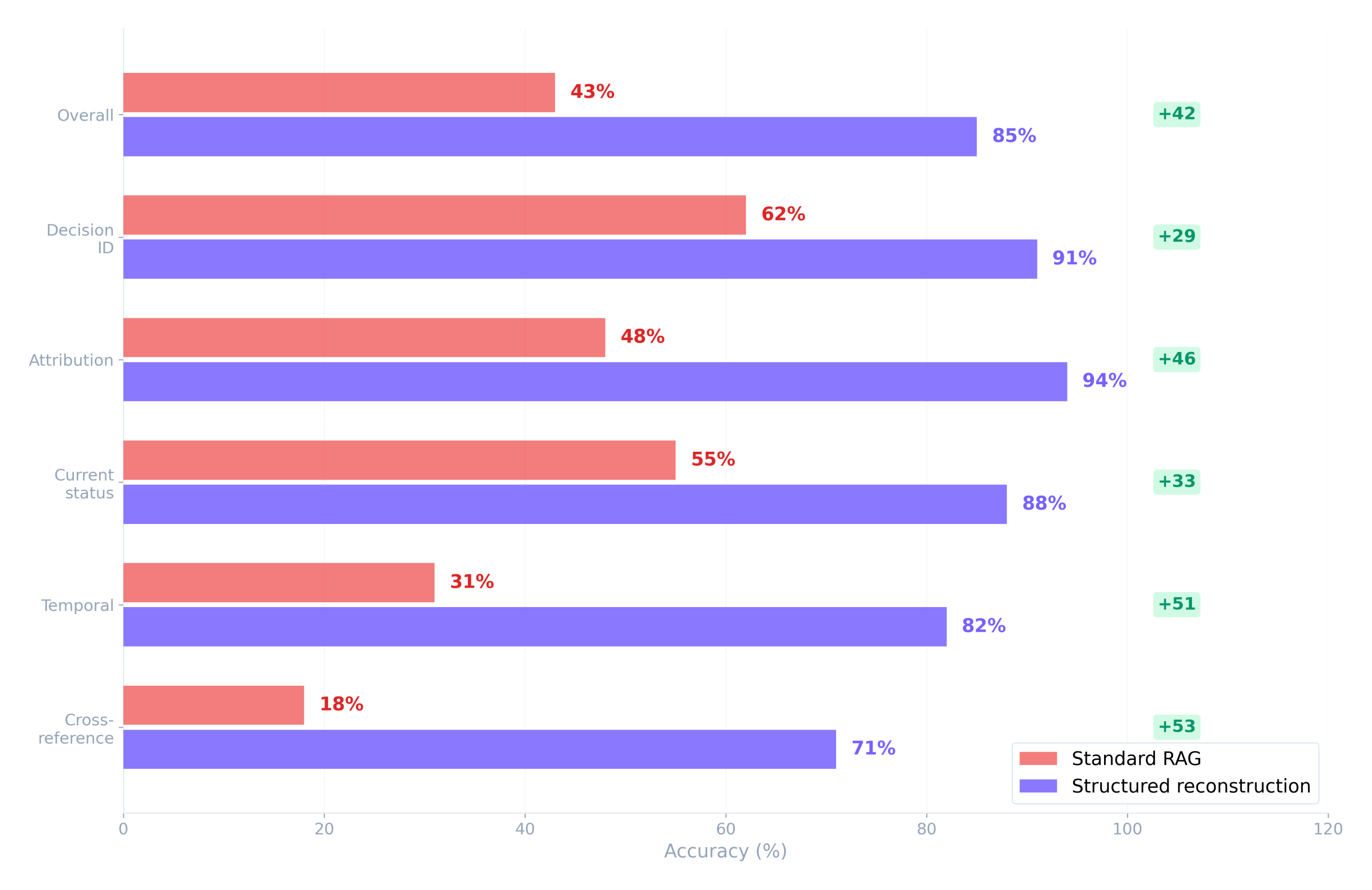
The 42-point overall gap came entirely from what happened to the email content before it reached the model. The model didn’t change between the two runs. The prompts didn’t change. The source threads didn’t change.
The categories where RAG performs worst, attribution and temporal and cross-reference, are exactly the categories that matter most for business email: who committed to what, what changed since last week, and how does this thread connect to a related discussion happening in a separate chain.
To make this concrete, consider asking “What’s the current status of the Meridian deal?” across these two pipelines.
Standard RAG returned:
Decision-maker: Mike Torres (most active in thread)
Status: Moving forward with 30-day POC
Pricing: Agreed at proposed rates
Next steps: Schedule kickoffThe structured pipeline returned:
{
"status": "at_risk",
"current_position": "POC approved, but two commitments from our side are overdue",
"decisions_made": [
{
"decision": "30-day POC with dedicated solutions engineer",
"decided_by": "Lisa Chen, VP Operations",
"date": "2026-01-14",
"source": "msg_18d4f (Jan 14, 15:22)"
}
],
"open_commitments": [
{
"commitment": "Send revised pricing with volume discount",
"owned_by": "us",
"status": "overdue",
"days_overdue": 74
}
],
"risk_signals": [
{
"type": "engagement_drop",
"detail": "Response time increased from same-day to 5+ days after Feb 10"
},
{
"type": "competitor_mention",
"detail": "Referenced evaluating an alternative, thread with James Park, Feb 22"
}
]
}The RAG version got the decision-maker wrong because Mike was the most talkative person in the thread, which made his name dominate the surrounding context. It missed the overdue commitments because those require matching a promise made in one message against the absence of follow-through across subsequent messages.
It missed the engagement drop because detecting that requires computing time deltas between consecutive replies, which no embedding model encodes. And it reported the deal as “moving forward” when two converging risk signals put it squarely at risk.
Every fact in the RAG output came from real messages in the thread. The conclusions were wrong because of what happened to the email content before the model saw it.
The instinct when output quality is poor is to improve the prompt, add guardrails, or upgrade to a more capable model. None of that addresses why the output is wrong, because the model is doing exactly what it’s designed to do: generating the most plausible completion given the input it received.
The input contained six copies of the original proposal and one copy of the final decision, so the model weighted the proposal more heavily. The input had no reliable attribution markers, so the model guessed based on name frequency. The input had no temporal ordering, so the model couldn’t distinguish superseded decisions from current ones.
Six things need to happen to email content before it reaches the model’s context window.

The six layers described above need to happen before email content reaches your model. Building them yourself is a real engineering project (our post on build vs. buy email context for AI agents covers the scope, which is consistently 3-6x what teams estimate at the start).
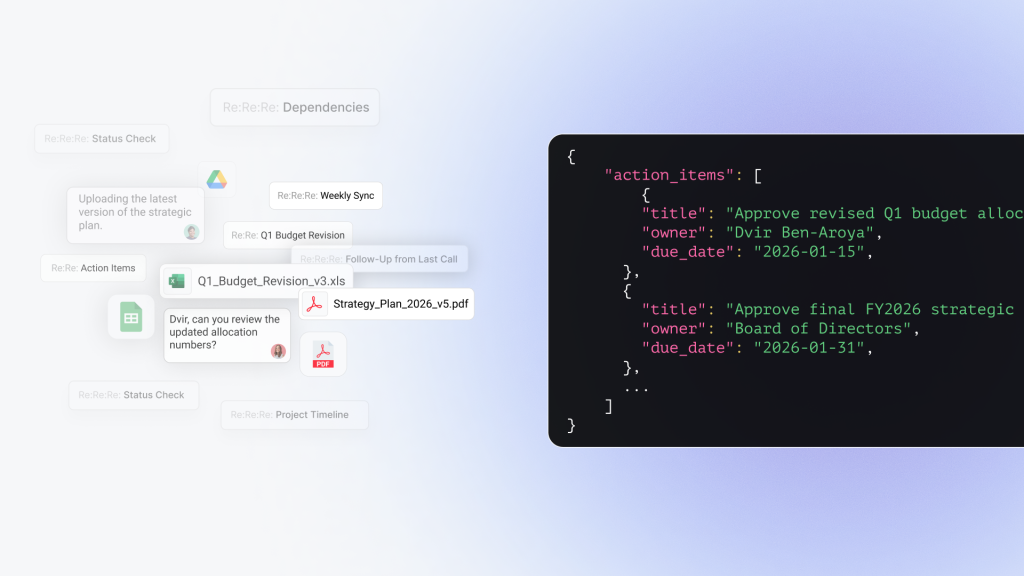
iGPT’s Context Engine handles all six in one API call: thread reconstruction, quoted text deduplication, participant attribution, temporal ordering, cross-thread linking, and attachment processing. The output is structured JSON with citations to source messages.
import os
from igptai import IGPT
igpt = IGPT(
api_key=os.getenv("IGPT_API_KEY"),
user="user_123"
)
response = igpt.recall.ask(
input=(
"What's the current status of the Meridian deal? "
"Include open commitments and risk signals."
),
quality="cef-1-high",
output_format="json"
)The structured output shown at the top of this post is what this actually returns. Try it on your own email data in the playground, paste “What’s the current status of [any deal or project name]?” and compare the output against what your current pipeline produces for the same thread.
If you use Claude on Pro or Max for work and you’ve ever wished it just knew what was going…
Connecting an AI agent to email is a six-layer problem, and most teams only budget for the first two. The…

Every inbox has threads that fell through the cracks. A prospect asked a question that never got answered. A proposal…