For three years, RAG was the default way developers connected AI to data: pull documents, chunk them, embed them, store the vectors, retrieve on query, pass the top results to the model.
It worked because the data it pointed to didn’t move. That has stopped being true for the questions people now want to ask.
The rest of this post is the diagnosis: what made RAG work, what specifically broke when the data changed shape, and what the systems that actually work in production do instead.
What Made RAG Work
Static documents have three properties that vector similarity handles well:
They don’t change. A product manual published in March reads the same in April. Embed once, query for years.
They answer their own questions. The answer to “how do I configure SSO?” lives in the SSO doc. No need to reach across files.
They’re basically plaintext. Whatever formatting exists is decoration. Strip it to raw text and nothing important is lost.
Under these three conditions, cosine similarity between an embedded query and embedded chunks gets you close enough to the right answer. The model cleans up the rest. The whole pipeline fit the shape of the data.
Why It Breaks
The data moved. The questions people now ask AI agents are questions about living systems: sales pipelines, customer accounts, contracts in flight, project states, and running negotiations. These are not documents. They are processes, and the artifacts they produce mutate constantly, reference each other constantly, and spread across systems that vector similarity cannot bridge.
Four of RAG’s assumptions fail at once.
1. The data keeps moving
Google Docs gets edited in place. Contracts get redlined between morning and afternoon. A pricing sheet updated an hour before a customer call is the version that matters. The one in your vector index from last night is the version that gets your customer the wrong number.
Every team ships with this pattern on day one:
# Sync docs once a night. Query against the index.
def nightly_sync():
docs = drive.files.list(q="mimeType='application/vnd.google-apps.document'")
for doc in docs:
content = drive.files.export(fileId=doc.id, mimeType='text/plain')
chunks = chunk_text(content)
vector_store.upsert(doc.id, chunks, embed(chunks))
def answer(query):
hits = vector_store.similarity_search(query, k=5)
return llm.generate(query, context=hits)
Between 02:00 and tomorrow, every edit is invisible to your agent.
“Just sync more often” is the first fix everyone tries. It doesn’t work. Full re-embedding is expensive, so 15-minute syncs become a cost line item. Shrinking the window doesn’t close it; any query inside the window still returns stale data. The only rate fast enough is real-time, and real-time is a different architecture.
2. The answer isn’t in one document
This is the whole argument in one sentence: RAG fails when the answer isn’t in a document.
Ask an AI, “What’s the refund policy in our Northwind contract?” and the contract in Drive will tell you the clause. Ask why the policy is what it is, and the answer is not in the contract at all. It’s in the email thread six weeks ago where the customer pushed back on 7 days, legal proposed 14, and the account exec agreed.
Vector similarity has no concept of a relationship. It has a similarity. It can find the chunk that contains the refund clause. It cannot find the thread that produced it.
Modern questions span sources:
Contract clauses ↔ email negotiations
Project plans ↔ Slack deadline slips
CS health scores ↔ unresolved tickets ↔ champion emails
Vendor terms ↔ procurement threads ↔ invoice history
RAG treats every corpus as an island. The answers live in the bridges.
3. Structure is the content
In a contract, a comment left by legal on clause 12.4 that says “this cap is too low, needs sign-off” is often the single most important fact in the document. A suggested edit sitting unaccepted for three weeks tells you more than the accepted text. A section heading frames what the paragraph under it means.
Watch what happens when a naive pipeline ingests a Google Doc:
# "Just give me the text"
content = drive.files.export(fileId=doc_id, mimeType='text/plain')
# → headings collapsed into paragraphs
# → tables collapsed into pipe-separated strings
# → comments stripped entirely
# → suggested edits invisible
# → revision history gone
The information that actually determines the answer is gone. Retrieval runs on what’s left: a degraded surface version of the data that looks fine but produces wrong answers.
4. There is no concept of who is asking
A service account ingests everything it can access. Retrieval runs against the full index. The LLM gets chunks from documents that the asking user may not be authorized to see.
# Indexed by a service account with workspace-wide access
def answer_question(user_email, query):
chunks = vector_store.similarity_search(query, k=5)
# ← nothing here checks what user_email can actually see
return llm.generate(query, context=chunks)
In a personal productivity demo, this is invisible. In a multi-tenant product, it’s the bug that ends companies.
None of these four problems is fixable by better chunking, better embeddings, or a larger context window. Larger context windows increase capacity. They don’t solve assembly. These failures are consequences of treating dynamic, relational, structured, permissioned data as if it were a PDF.
What Systems That Actually Work Do Instead
This isn’t an incremental improvement to RAG. It’s a different layer in the system.
The systems running in production against live business data share five properties:
Change-driven sync. Watch the provider’s change feed and reindex what changed in near real time. No nightly batches. The index is never more than seconds behind the doc.
Cross-source linking. A contract and the thread that produced it are connected as first-class edges, not hoped for by similarity. Traversal across sources happens before the model runs, not after.
Structure preserved. Headings, tables, comments, and suggestions are retained as semantic signals, not flattened to plaintext. A comment on clause 12.4 is retrievable as a comment on clause 12.4.
Permissions enforced at query time. The asking user’s access is checked against the live provider, not inferred from what the service account indexed. The provider remains the source of truth for what each user can see.
Outputs as structured data. Schema-bound JSON, not a pile of chunks. Your application consumes fields, not prose.
Every one of these is an answer to one of the four failure modes above. None of them is optional for live business data. All of them are six-month projects to build from scratch.
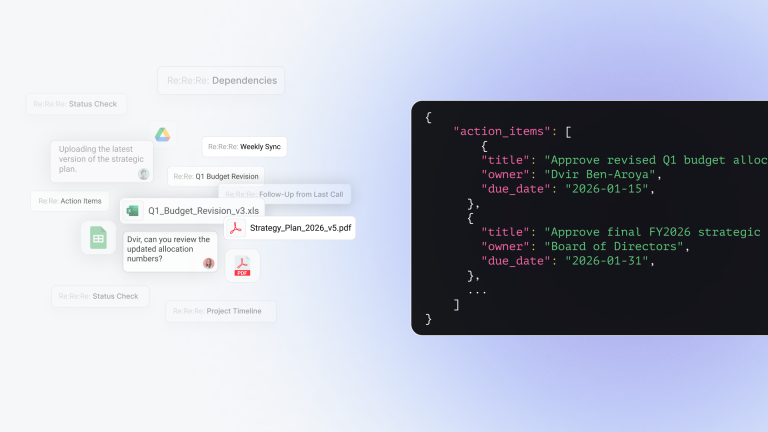
This is where systems like iGPT come in. Instead of building and maintaining that pipeline, the developer makes one call and gets back context that’s already assembled: current state, linked sources, structure preserved, permissions enforced, output in a format an agent can actually use.
from igptai import IGPT
igpt = IGPT(api_key=os.getenv("IGPT_API_KEY"))
context = igpt.recall.ask(
user_id="alex@yourco.com",
query="What's the current refund policy in our Northwind MSA, and why?"
)
The point isn’t convenience. It’s the hard parts, the ones that broke RAG, that are handled before the model ever runs.
The Handoff
RAG still works. Just not for this class of problems.
For static documentation, it will remain fine for years. For anything that looks like a business process, it is already failing, and the teams shipping on it are starting to notice that no amount of tuning recovers the ground the architecture gives up.
The interesting products of the next two years will be built on context, not retrieval. The teams that figure this out early will look, in hindsight, like they had an advantage. They didn’t. They just noticed the shift sooner.